
LSM Tree Explained
LSM Tree – Log-Structured Merge Tree
An LSM Tree is a data structure commonly used in databases to efficiently handle high-volume write operations. It’s particularly popular in systems where data is mostly written in large quantities (e.g., time-series databases, key-value stores, and log management systems). LSM Tree works by organizing data in layers and leveraging a combination of in-memory and on-disk data structures to ensure highly writes efficient without dropping read speed. However, read speed will be not as efficiet as in rdbms (e.g. postgress DB) as those are read optimized. In lsm tree implementation, read speed depends on the multiple parameters which will be discussed in the next sections.
Why LSM Tree is write efficient?
It writes into memory rather than disk (storage) which makes it superfast. Lets explore how it works and its terminology and architecture.
High-Level LSM Tree Architecture
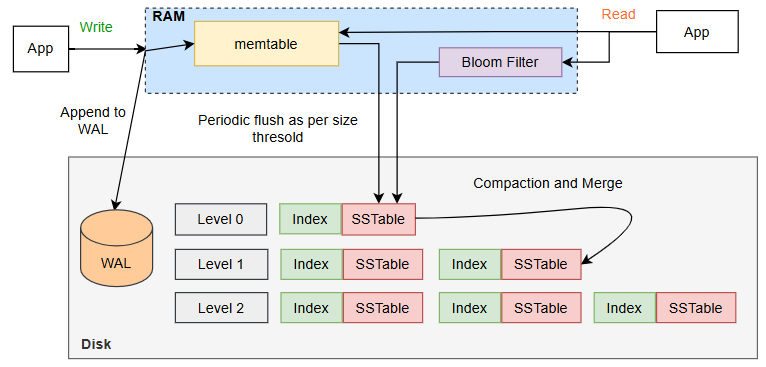
In LSM Tree, there two types of operations which are important.
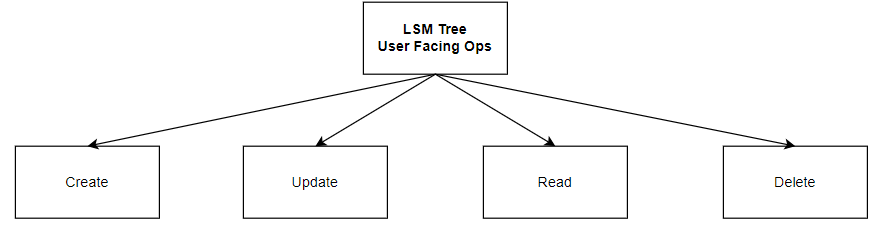
- User Operations in LSM Tree (User facing)
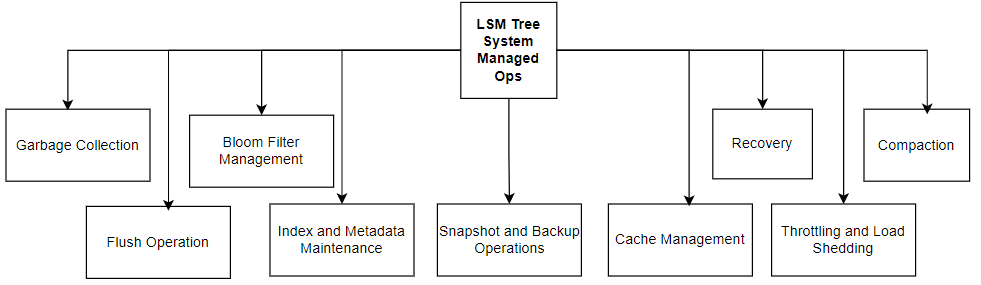
- Backend Operations (System-Managed)
Lets go deeper inunderstanding the above operations along with understanding how LSM Tree works:
Write (insert)/Update Operation:
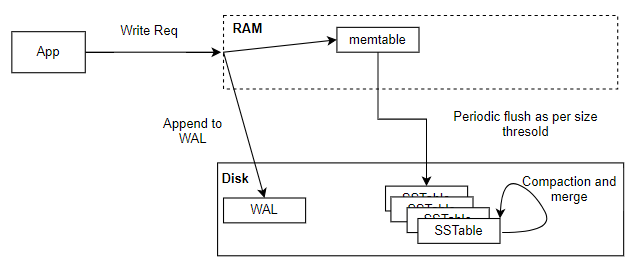
- When a user initiates a Create operation, Data gets inserted a new record or key-value pair into the database. In an LSM (Log-Structured Merge) Tree, data is initially stored an in-memory structure called the Memtable (a write-friendly structure, often implemented as a sorted tree or hash table), so this write is not directly made to disk which makes it write efficient.
- Data in the Memtable is kept sorted, facilitating fast searches and inserts without needing immediate access to disk storage.
- For durability, each insertion operation is also written to the Write-Ahead Log (WAL).
- The WAL is a sequential log file where each write is recorded before it’s added to the Memtable, ensuring data isn’t lost if there’s a system crash before it’s persisted to disk.
- The WAL is typically stored on disk and append-only, making it fast for sequential writes.
- Over time, as more data is inserted, the Memtable fills up. And when it reaches a predefined threshold (based on memory limits), a Flush Operation is triggered, which moves the contents of the Memtable to disk.
- The flush process writes data to a Sorted String Table (SSTable) on disk, which is an immutable, sorted file format optimized for LSM Trees. SSTable consists of two components - Index & Data Block. The Index block contains the primary keys and offsets, which point to the key-value offset in the Data block where the data is stored.
- SSTables are write-once and append-only, meaning that each SSTable is created once and not modified after being written. In case of an update to an existing key, a duplicate entry is recorded in the latest sstable and during compaction step old entry gets deleted. So at some point of time duplicate entries are possible to exist. And if read happens for the same key, it always gets the latest data even if more duplicates are present becasue read always happens from the latest sstable to oldatest table.
- SSTables store the flushed Memtable data in a sorted manner, enabling efficient retrieval and minimizing the need for random disk access during reads.
- Over time, multiple SSTables accumulate on disk, which can cause inefficiency and redundancy.
- A Compaction process periodically merges these SSTables, removing duplicates and consolidating data to reduce disk space usage.
- This process ensures that reads are more efficient by minimizing the number of SSTables that need to be accessed to retrieve data.
- To speed up reads, each SSTable includes a Bloom Filter and Index structures.
- Bloom Filters provide a probabilistic way to test if a key exists in an SSTable without scanning the entire file.
- An index helps locate specific keys within the SSTable quickly, so reads don’t have to search the entire structure. All the sstable are indexed for the efficient read operation.
Read Operation:
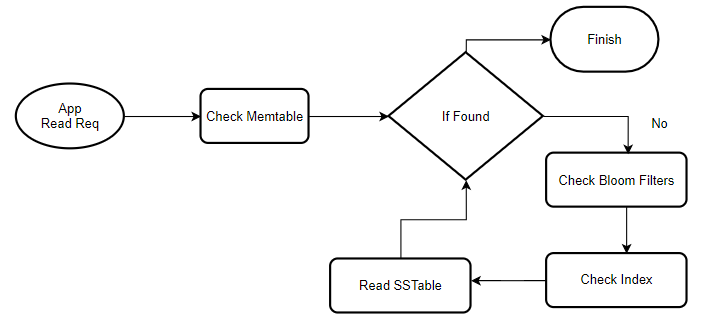 The read operation in an LSM Tree starts when a user requests to retrieve a specific key or data. Since data is spread across both memory (in the Memtable) and disk (in multiple SSTables), the system (DB) must check multiple locations to retrieve the latest value for a key. The search process begins in the Memtable, as it contains the most recent data, including updates not yet flushed to disk. If the key is found here, the value is returned immediately. However, if the key is not found in the Memtable, the system then checks the SSTables on disk. To speed up this process, each SSTable is accompanied by Bloom Filters and indexes. Bloom Filters, probabilistic data structures, help quickly rule out SSTables that do not contain the key, reducing unnecessary file accesses. If a Bloom Filter indicates the possible presence of a key, the system uses the SSTable’s internal index to locate the exact position of the key in the file.
The read operation in an LSM Tree starts when a user requests to retrieve a specific key or data. Since data is spread across both memory (in the Memtable) and disk (in multiple SSTables), the system (DB) must check multiple locations to retrieve the latest value for a key. The search process begins in the Memtable, as it contains the most recent data, including updates not yet flushed to disk. If the key is found here, the value is returned immediately. However, if the key is not found in the Memtable, the system then checks the SSTables on disk. To speed up this process, each SSTable is accompanied by Bloom Filters and indexes. Bloom Filters, probabilistic data structures, help quickly rule out SSTables that do not contain the key, reducing unnecessary file accesses. If a Bloom Filter indicates the possible presence of a key, the system uses the SSTable’s internal index to locate the exact position of the key in the file.
In cases where there are multiple versions of a key (due to delayed compaction), the system relies on timestamps to ensure it returns the most recent version. Thus, even with multiple sources of data, the LSM Tree can effectively manage read requests, maintaining efficient access by balancing in-memory structures, on-disk files, and background maintenance tasks like compaction and indexing. This architecture allows LSM Trees to handle high write throughput while keeping reads optimized and manageable across both memory and disk.
Notes: Bloom Filters and Index are associated with the SSTable. So to get the required data, DB iterates through SSTables, Bloom Filters, and Index until data is retrieved or all SSTables are exhausted.
Compaction and merge:
compaction and merge processes are used to manage and optimize data storage by consolidating data from smaller, faster components (or levels) to larger, slower ones. Although these steps are costly process need to handle it efficiently. But these steps are much needed to get the following:
- Optimize read efficiency: By keeping the number of files that need to be read during a query low
- Reclaim Storage: By deleting the obsolete or duplicate data to reduce storage usage.
- Maintains Write Efficiency: By deferring and batching writes through these processes, LSM-Trees reduce write amplification compared to constant updates in place.
Lets understand how it works:
Merge
- In an LSM-Tree, data is organized in multiple levels (e.g., Level 0, Level 1, etc.), with each level potentially having larger storage limits than the one before.
- Data is initially written to the memtable. When the memtable reaches capacity, it is flushed to disk as a sorted file at Level 0.
- Data flows from lower to higher levels. Files in Level 0 may be merged into Level 1 when they reach a threshold. In a merge process, files from one level are merged with the files in the next level, and duplicates or old entries are compacted.
Compaction
- Compaction can be triggered based on various thresholds, such as the number of files or the total file size at a particular level. These triggers can be either automated based on various thrsold and system usage patterns or can be manul or can be combination of both
- A set of files is selected for compaction, often from one or multiple levels (e.g., all files in Level 0).
- The selected files are scanned, and their data is merged into a new, larger file. Any duplicate keys are resolved, keeping only the latest version.
- The newly merged file is written to the next level in the LSM-Tree. Old files are deleted once compaction is successful.